[study] 카프카 설치하면서 알게 된 내용 정리
내부 동작 원리와 용어 등
[study] 카프카 설치하면서 알게 된 내용 정리
들어가며: 카프카 설정하며 알고 싶었던 내용 정리
카프카를 EC2에 직접 설치하며 브로커 설정에 대해 의문이 생김.
아래처럼 listeners와 advertised.listeners를 sed로 수정하는데, 이 두 설정이 어떤 차이가 있고 결과적으로 어떻게 반영되는지 궁금해졌다.
1
2
3
# server.properties 수정 예시
sed -i 's|^#listeners=.*|listeners=PLAINTEXT://0.0.0.0:9092|' /opt/confluent/etc/kafka/server.properties
sed -i 's|^#advertised.listeners=.*|advertised.listeners=PLAINTEXT://'"$(curl -s http://169.254.169.254/latest/meta-data/public-ipv4)"':9092|' /opt/confluent/etc/kafka/server.properties
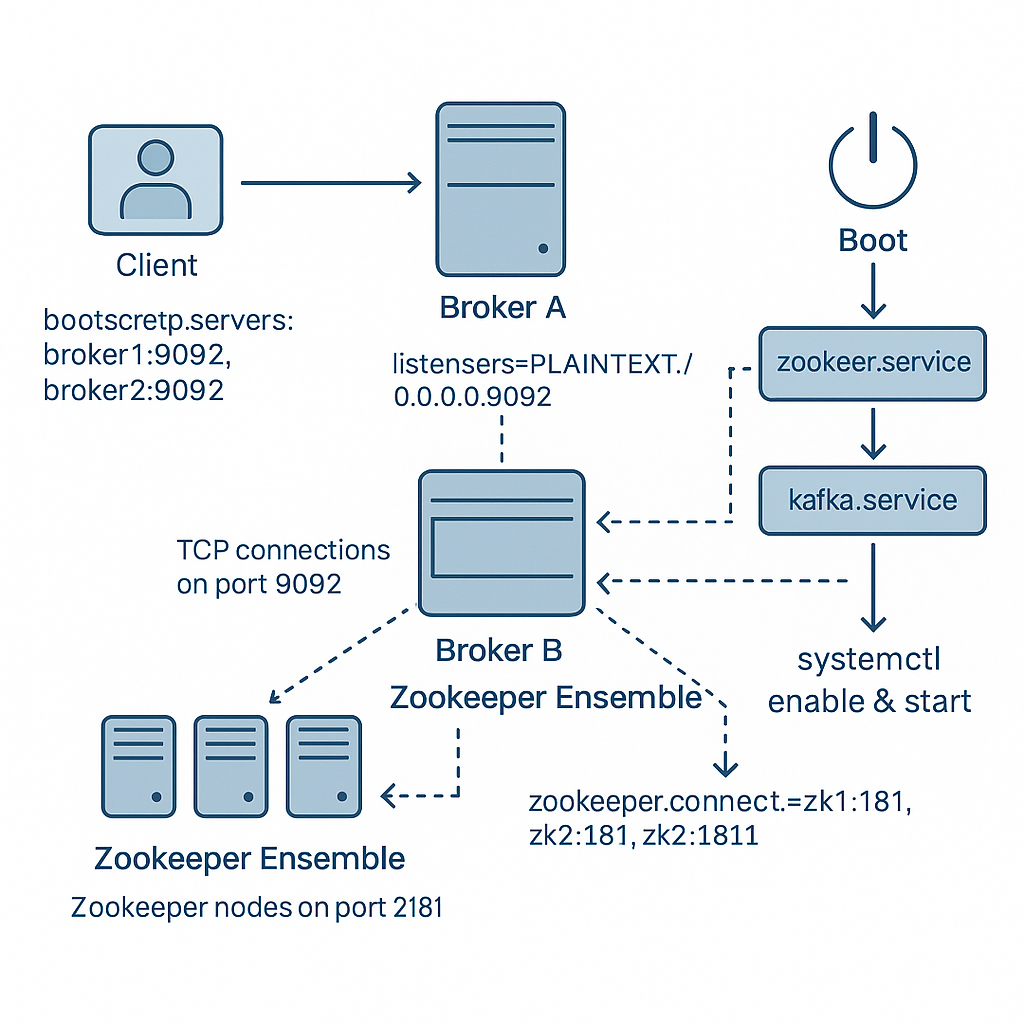
이 다이어그램을 바탕으로 각 설정이 어떤 역할을 하고 전체 흐름이 어떻게 흘러가는지 단계별로 살펴보자.
클러스터 핵심 구성 요소 한눈에 보기
-
Kafka Cluster : 브로커들의 집합합
- Apache ZooKeeper
- 카프카가 제대로 작동하려면 누가 리더인지, 어떤 브로커가 살아있는지 등을 계속 확인해야한다.
- 파티션의 리더를 정하거나, 전체 시스템 상태를 추적할 때 사용
- Kafka Connect
- 카프카와 다른 시스템(DB, 파일, 클라우드 저장소 등)을 연결해주는 도구
- 소스 커넥터: 외부에서 Kafka로 데이터를 가져옴 (예: MySQL → Kafka)
- 싱크 커넥터: Kafka에서 외부로 데이터를 내보냄 (예: Kafka → Elasticsearch)
- 외부 데이터는 적절한 형식으로 변환됨.
- 카프카와 다른 시스템(DB, 파일, 클라우드 저장소 등)을 연결해주는 도구
- Kafka MirrorMaker
- 데이터 센터 내부 또는 여러 데이터 센터 간에 두 Kafka 클러스터 간에 데이터를 복제
- 소스 Kafka 클러스터에서 메시지를 가져와 대상 Kafka 클러스터에 작성성
- Kafka Bridge
- HTTP 기반 클라이언트를 Kafka 클러스터와 통합하기 위한 API를 제공
- Kafka Exporter
- Kafka가 잘 작동하고 있는지 확인하기 위해 메트릭을 모니터링 해야함.
- 이러한 Prometheus 메트릭 분석을 위한 데이터 모니터링 도구
세부 설정에서 궁금했던 내용
1) Client → bootstrap.servers
- 카프카는 클라이언트(Producer/Consumer)들이 Kafka 브로커에 접속해서 메시지를 주고받는 구조
- 이 클라이언트들은 Kafka 브로커가 어디에 있는지(=IP와 포트) 알아야 한다. 그래서
bootstrap.servers에 명시된 브로커 주소 목록을 사용한다. (진입지점점)1
bootstrap.servers=broker1:9092,broker2:9092
- 이 중 하나에 TCP 연결을 맺으면, 해당 브로커로부터 “이 클러스터에는 A, B, C 브로커가 있다”는 메타데이터를 전달받아 이후 통신에 활용한다.
2) listeners vs. advertised.listeners
| 설정 항목 | 역할 |
|---|---|
| listeners | 브로커 프로세스가 바인딩(bind) 할 네트워크 인터페이스/포트 (예: 0.0.0.0:9092 → 모든 인터페이스 수신) (내가 어디서 들을지) |
| advertised.listeners | 클라이언트에게 알려줄(advertise) 실제 접근 주소/호스트명 (예: 퍼블릭 IP 또는 DNS) (클라이언트에게 나를 이렇게 소개할게) |
listeners=PLAINTEXT://0.0.0.0:9092
브로커가 내부적으로 9092 포트를 열어 모든 인터페이스에서 연결을 받는다.advertised.listeners=PLAINTEXT://ec2-XX-XX-XX-XX.compute.amazonaws.com:9092
클라이언트가 “메시지 주고받을 땐 이 호스트명으로 접속해라”라고 안내하는 설정이다.
3) 브로커 간 TCP 연결 (Kafka Cluster 내부 통신, port 9092)
- 도식에서 카프카 클러스터 내부에는 여러 브로커(서버)가 포함됨
- 이 브로커들은 내부적으로 TCP로 연결되어 있으며 주로 9092를 사용해 통신한다.
- 이러한 통신은
- 메타데이터 동기화: 어떤 토픽이 어디에 있고, 어떤 파티션의 리더가 누구인지 등 정보를 공유
- 리더 선출: 특정 파티션에 장애가 생기면, 다른 브로커가 리더가 되는 과정을 수행
- ISR (In-Sync Replica) 유지: 각 브로커가 복제본을 얼마나 잘 따라오고 있는지 확인하기 위해 필요하다.
4) Zookeeper Ensemble 연동 (port 2181)
- Zookeeper 클러스터(
2181)에 각 브로커가 자신을 등록(register) 하며, 이후 다음 기능을 수행한다.- 컨트롤러 선출: ZooKeeper는 클러스터 내에서 하나의 컨트롤러 브로커(controller broker) 를 선출하고 이 컨트롤러가 전체 클러스터의 리더 선출 및 상태 관리를 조율한다.
- 메타데이터 저장소: 토픽, 파티션, 브로커 목록 등 클러스터 구성을 상태 정보로 저장하여 브로커 간 공유를 가능하게 한다.
- 브로커 멤버십 관리: Kafka 브로커의 접속/종료 상태를 감지하여 동적으로 클러스터 구성을 반영한다.
- 설정 예시:
1
zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
요약하자면, 브로커 간 TCP 연결(9092)은 Kafka 내부의 실시간 동작을 위한 통신 채널이고 / ZooKeeper(2181)는 클러스터의 전체 상태를 관리하고 컨트롤러를 선출하는 외부 조정자 역할을 한다.
추가 할 일) systemd를 활용한 자동 기동
- unit 파일 작성
/etc/systemd/system/zookeeper.service/etc/systemd/system/kafka.service
- enable & start
1 2 3
sudo systemctl daemon-reload sudo systemctl enable zookeeper.service kafka.service sudo systemctl start zookeeper.service kafka.service
- 부팅 순서 보장
After=network.target→ 네트워크 활성화 후 ZK 기동After=zookeeper.service→ ZK 이후 Kafka 기동
마치며: 정리 및 다음 단계
bootstrap.servers, listeners vs. advertised.listeners, 브로커 간 통신, Zookeeper, systemd 자동 기동까지 핵심 흐름을 설명했다.
다음은 위 설명을 기반으로 구성한 단일 카프카 클러스터를 활용해, Lambda → Kafka 연동 → S3 배치 적재 등 데이터 파이프라인 구축 과정을 다뤄보겠다. 끝!
이 기사는 저작권자의
CC BY 4.0
라이센스를 따릅니다.