웹 클릭스트림 수집하기 5) Kafka Connect S3 Sink 설정
커넥터 실패 오류 확인 및 해결 과정 정리
카프카 S3 커넥터 설정에서 겪은 애로사항
커넥터를 설치하고 구동하는데에는 큰 문제가 없었습니다. 하지만 정상적으로 구동이 되는지 확인하고 더 이해해야할 문제들이 있어 오늘은 이와 관련된 내용들을 작성해보려고 합니다.
🎯 이번 글 목표
지난 글에 이어서 오늘은 카프카를 통해 커넥터를 만들었던 과정 중 아래와 같은 문제와 그를 통해 배운 점을 정리해보겠습니다.
- S3 전송 올바르게 되는지 확인
- 저장된 데이터의 경로 오류 수정
- Kafka Connect S3 Sink 역할 정리
1. S3 전송 올바르게 되는지 확인
카프카 커넥터를 설정하고 S3로 데이터를 잘 전송하는지 알 수 없는것이 가장 큰 문제였습니다. 그래서 저는 우선 S3에 저장하는 데이터의 양을 줄여 잘 전송되는지 확인했습니다.
/opt/confluent/etc/kafka/quickstart-s3.properties
1
2
3
4
5
s3.region=ap-northeast-2
s3.bucket.name=<버킷 이름>
s3.part.size=67108864
#flush.size=1000
flush.size=100
여기서 flush.size는 하나의 S3 오브젝트에 기록할 최대 레코드 수를 지정하는 설정입니다. 각 파티션당 1000개의 레코드를 기록한 뒤에 현재 파일을 닫고 S3에 업로드하며 새로운 파일 작성을 시작하도록 설정되었습니다.
이를 100으로 수정하고 S3 버킷에 정상 저장되는지 확인했습니다.
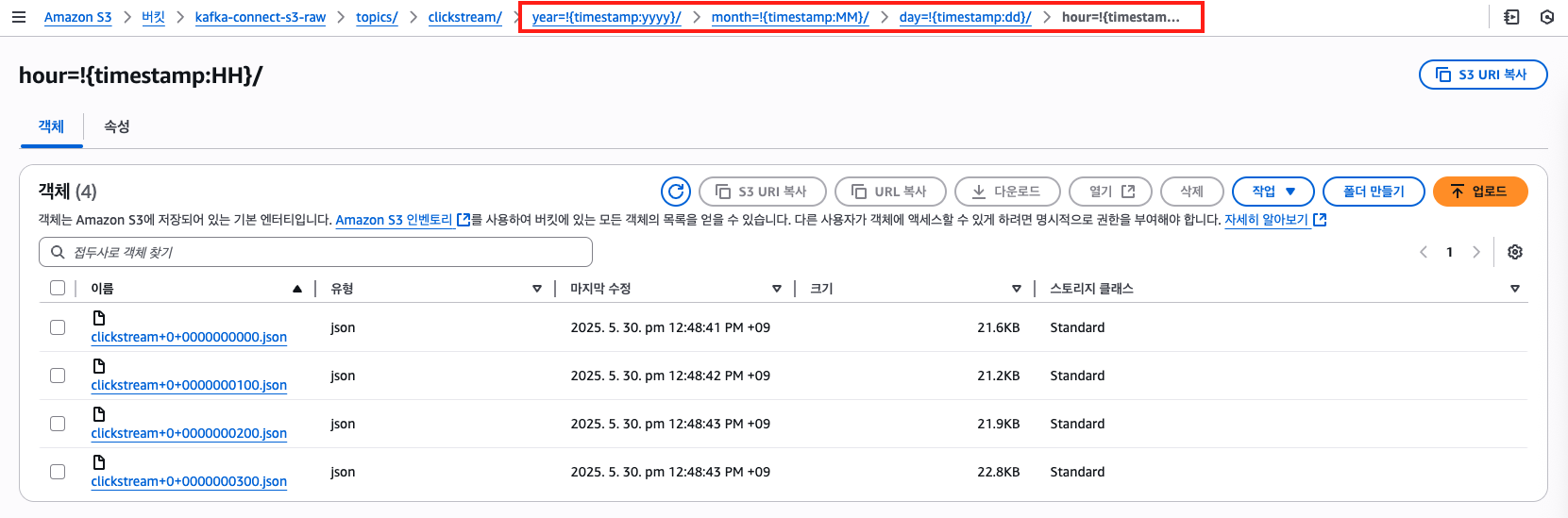
위와같이 100건씩 나눠서 올바르게 json 파일로 저장되는 것을 확인할 수 있었습니다.
그런데… 저장 경로에 날짜가 정상적으로 기록되어야 하는데 이상한 형식으로 기록되는 것을 발견했습니다!
2. 저장된 데이터의 경로 오류 수정
/opt/confluent/etc/kafka/quickstart-s3.properties
1
2
3
4
5
6
7
partitioner.class=io.confluent.connect.storage.partitioner.TimeBasedPartitioner
schema.compatibility=NONE
partition.duration.ms=3600000
path.format='year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}'
locale=ko_KR
timezone=Asia/Seoul
해당 파일에서 path.format 형태와 동일하게 기록되는 내용을 확인하고 이 부분이 문제가 있다고 생각해 수정하고자 했습니다.
공식 문서에는 시간 단위로 파티셔닝하고 저장하는 방식을 설정하는데 partitioner.class=io.confluent.connect.storage.partitioner.HourlyPartitioner를 사용하는 것을 설명하고 있어 해당 방식으로 수정했습니다.
1
2
3
4
5
6
7
partitioner.class=io.confluent.connect.storage.partitioner.HourlyPartitioner
schema.compatibility=NONE
#partition.duration.ms=3600000
#path.format='year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}'
locale=ko_KR
timezone=Asia/Seoul
[참고] 커넥터 재실행과 내용 확인
저는 사전에 등록해놓은 systemd를 통해 재실행했습니다.
1
2
3
4
5
6
7
$ sudo systemctl restart kafka-connect.service
$ sudo systemctl status kafka-connect.service
kafka-connect.service - Kafka Connect Standalone (S3 Sink)
Loaded: loaded (/etc/systemd/system/kafka-connect.service; enabled; vendor preset: disabled)
Active: active (running) since 금 2025-05-30 04:07:28 UTC; 44min ago
Main PID: 13292 (java)
CGroup: /system.slice/kafka-connect.service
그리고 커넥터 연결이 정상적으로 작동하는지 확인하기 위해 다음과 같이 curl 요청을 보냈습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
$ curl -s http://localhost:8083/connectors/s3-sink/status | jq .
{
"name": "s3-sink",
"connector": {
"state": "RUNNING",
"worker_id": "10.0.10.128:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "10.0.10.128:8083"
}
],
"type": "sink"
}
이제 다시 실행된 결과를 확인해보면 다음과 같이 경로가 원하는 시간별로 되어있는 것을 확인할 수 있습니다.
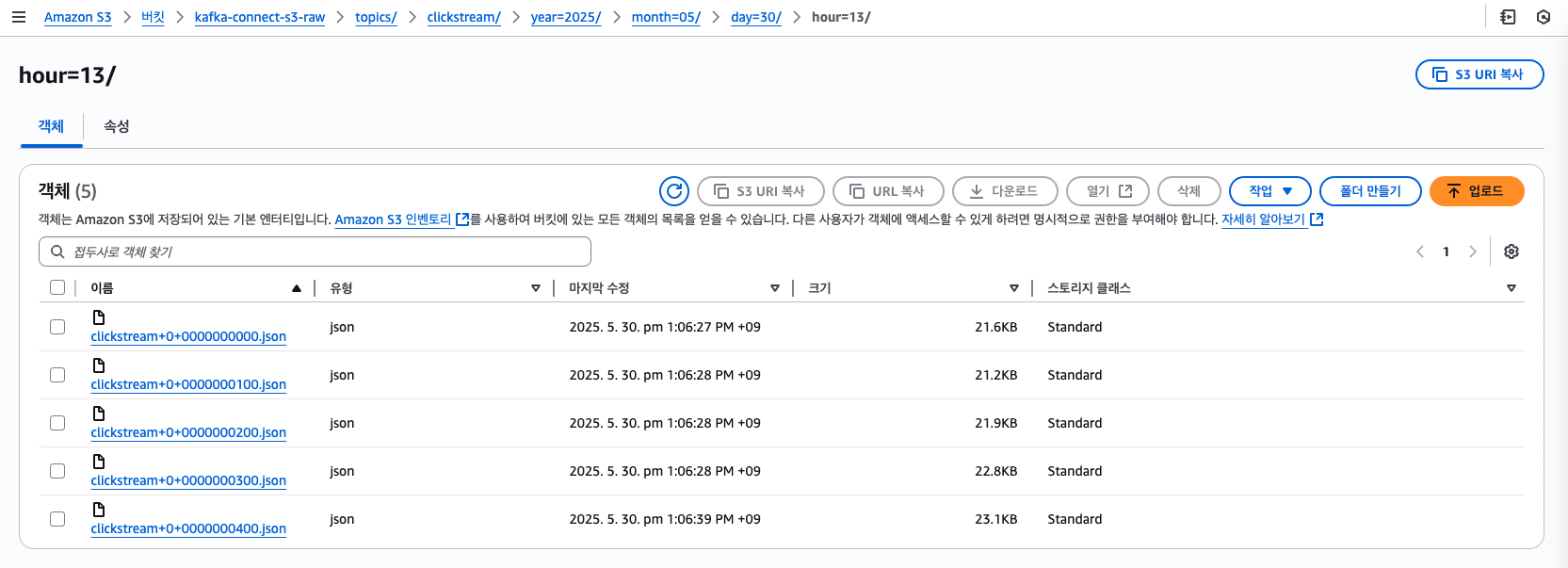
마지막으로 해당 내용을 확인한 후에 처음 설정한 100건 json 저장을 1000건으로 되돌리고 동일하게 재시작 해주었습니다.
3. Kafka Connect S3 Sink 역할 정리
마지막으로 해당 트러블 슈팅을 통해 알게된 커넥터의 역할에 대해 정리해보려고 합니다. Kafka Connect S3 Sink 커넥터는 Kafka 브로커와 S3 사이를 연결해 주는 독립 프로세스입니다.
3.1 Consumer 역할 수행
KafkaConsumer 인스턴스를 생성해 토픽에서 poll() 방식으로 메시지를 가져옵니다.
- 파티션별로 내부 버퍼에 기록(
flush.size나 시간 기반 회전 조건 등) - 버퍼 조건 충족 시 S3에 업로드 → 그 시점까지 읽은 마지막 오프셋을 커밋(commit)
3.2 Offset 커밋과 메시지 보존
- Kafka에서 오프셋(offset) 은 파티션(Partition) 내 메시지의 순차적 번호입니다.
- 오프셋 커밋은 다음에 어디서부터 읽을지를 저장하는 것입니다. 토픽의 메시지를 즉시 삭제하지 않습니다.
- 실제 메시지 삭제는 브로커의
log.retention.ms또는log.retention.bytes정책에 따라 이루어집니다.
- 실제 메시지 삭제는 브로커의
- 커넥터가 장시간 오프셋을 갱신하지 않으면(
offsets.retention.minutes) 재시작 시 처음부터 읽기가 발생할 수 있습니다. 그래서 커넥터를 재시작했을 때 기존 데이터도 같이 저장됩니다.
3.3 브로커와 커넥터 개념
- 브로커: 토픽 저장, 파티션 관리, 복제(replication), 보존(retention) 담당
- Connect Worker: 컨슈머 역할만 수행하는 독립 JVM 프로세스
- Standalone 모드나 Distributed 모드로 운영할 수 있으며, 실제 프로덕션 환경에서는 다수 호스트에 분산 배포해 가용성과 확장성을 확보합니다.
3.4 현재 구성 방식과 이후 확장 방식
- 단일 서버로 테스트, 개발용으로 편리하나 장애 시 브로커와 커넥터가 동시에 영향을 받을 수 있습니다.
- 이후 분산 서버로 두어 브로커 클러스터와 별도의 Connect 클러스터를 두고 Connect 노드를 늘려 처리량을 확장할 수 있습니다.
- 추가로 모니터링 서버를 구축해 Prometheus + Grafana로 오프셋 지연과 에러를 모니터링 해야합니다.
🚀 결론 및 이후 계획
커넥터가 내부적으로 컨슈머처럼 읽고 버퍼링한 뒤, S3에 올리고 오프셋을 커밋하는 핵심 흐름을 가지고 있다는 전체 과정을 배우는 과정이었습니다. 시간 단위로 올바르게 설정하는 방법과 레코드 수를 수정해보면서 저장된 데이터를 확인하고 두 데이터가 동일하게 저장되는 것을 보고 오프셋을 이용한 방식으로 카프카가 레코드를 저장하고 메시지를 관리하는지 전반적으로 이해하게 되었습니다.
다음으로는 본격적으로 해당 데이터를 HDFS에 파일로 변환하는 과정을 다뤄보겠습니다.