카프카 개념 알고 가기
웹 클릭스트림을 전달할 카프카 두두등장
비동기 통신 패턴을 제공하는 분산 스트리밍 플랫폼, Kafka
데이터 엔지니어로 지원하기 전까지 저는 주로 Hadoop이나 Spark 같은 배치 처리 프레임워크만 익히 들어 알고 있었습니다. 그런데 최근 데이터 엔지니어 채용 공고를 살펴보니 Kafka를 요구하는 곳이 점점 늘어나고 있는 것 같아 이번 기회에 한 번 익혀보자는 마음으로 시작했습니다.
실시간으로 쏟아지는 대용량 이벤트 데이터를 안전하고 효율적으로 다룬다는 점에서 Kafka가 업계 표준으로 자리 잡았다는 이야기를 보았는데요. 이 글에서 그런 Kafka의 핵심 개념과 작동 방식을 자연스럽게 이해할 수 있도록 차근차근 정리해 보겠습니다.
카프카?
Kafka는 기본적으로 프로듀서가 메시지를 큐에 저장하고, 컨슈머가 이를 꺼내가는 메시지 큐 시스템입니다.
- 프로듀서는 메시지를 생성하고 전송합니다.
- 컨슈머는 메시지를 수신하고 처리합니다.
RabbitMQ나 ActiveMQ 같은 기존 메시지 브로커와 유사하지만, Kafka만의 특별한 특징이 있습니다.
가장 큰 차이점은 디스크 기반의 로그 저장입니다.
Kafka는 메시지를 메모리나 인메모리 큐가 아니라, 브로커라고 불리는 서버의 파일 시스템에 순차적으로 기록합니다.
- 브로커의 역할
- 네트워크 중계자로써 프로듀서와 컨슈머 간의 메시지 전달을 담당합니다.
- 리더 브로커는 파티션의 주 복사본을 저장하고, 팔로워 브로커는 복사본을 저장합니다.
이 덕분에
- 데이터 영속성이 높고
- 대량 메시지를 효율적으로 처리할 수 있으며
- 소비자가 언제든 과거 메시지를 다시 읽어올 수 있습니다.
이처럼 Kafka의 핵심 설계는 “안전하고 빠르게, 그리고 유연하게 대용량 메시지를 주고받는 것”에 집중되어 있습니다. 아래는 이를 가능하게 하는 주요 개념들입니다.
토픽과 파티션이 필요한 이유
Kafka에서는 먼저 토픽(topic) 으로 메시지의 주제를 나눕니다. 예를 들어 웹 클릭 로그를 다루는 토픽, 사용자 알림을 다루는 토픽처럼요. 이토록 메시지를 논리적으로 구분해 두면, 각 서비스는 자신이 관심 있는 토픽만 구독해서 처리할 수 있습니다.
하지만 “하나의 토픽” 안에 수백 기가바이트·초당 수천 건의 메시지가 몰리면 단일 서버로 감당하기 어렵겠죠? 그래서 Kafka는 토픽을 파티션(partition) 이라는 작은 물리적 단위로 나눠 저장합니다. 파티션 덕분에
- 병렬 처리가 가능해집니다. 여러 브로커(서버)에 파티션을 분산 배치하고, 여러 프로듀서/컨슈머가 동시에 읽고 쓸 수 있죠.
- 확장성을 확보할 수 있습니다. 처리량이 늘어나면 브로커를 추가하고 파티션 수만 늘리면 됩니다.
내결함성과 내구성은 왜 중요할까
실제 서비스에서 서버 한 대가 다운되었을 때 데이터가 사라지면 안 되겠죠? Kafka는 각 파티션을 여러 브로커에 복제(replication) 합니다.
- 브로커 A가 장애를 겪어도, 브로커 B나 C에 복제된 메시지를 그대로 이용해 계속 서비스를 유지할 수 있어요.
- 또, “acks” 설정을 통해 프로듀서가 “메시지가 디스크에 안전하게 기록된 시점”을 확인할 수도 있습니다.
이렇게 하면 네트워크나 하드웨어 이슈에도 메시지 유실 걱정 없이 안정적인 파이프라인을 만들 수 있습니다.
컨슈머 그룹으로 유연하게 처리 부하 분산
마지막으로 Kafka는 메시지를 “한 번만 처리하고 싶을 때”와 “여러 서비스가 각각 처리할 때”를 모두 지원합니다.
- 컨슈머 그룹(Consumer Group) 을 사용하면, 같은 그룹 내 여러 애플리케이션 인스턴스가 서로 역할을 나눠 각 파티션의 메시지를 중복 없이 가져갑니다.
- 반면, 서로 다른 그룹으로 구분하면 같은 메시지를 여러 곳에서 독립적으로 읽도록 할 수도 있습니다.
이 구조 덕분에
- 서비스 수평 확장이 쉽고,
- 장애 복구를 자동으로 처리하며,
- 메시지 재생(replay) 기능으로 과거 데이터를 다시 처리해볼 수도 있죠.
전체 흐름 요약
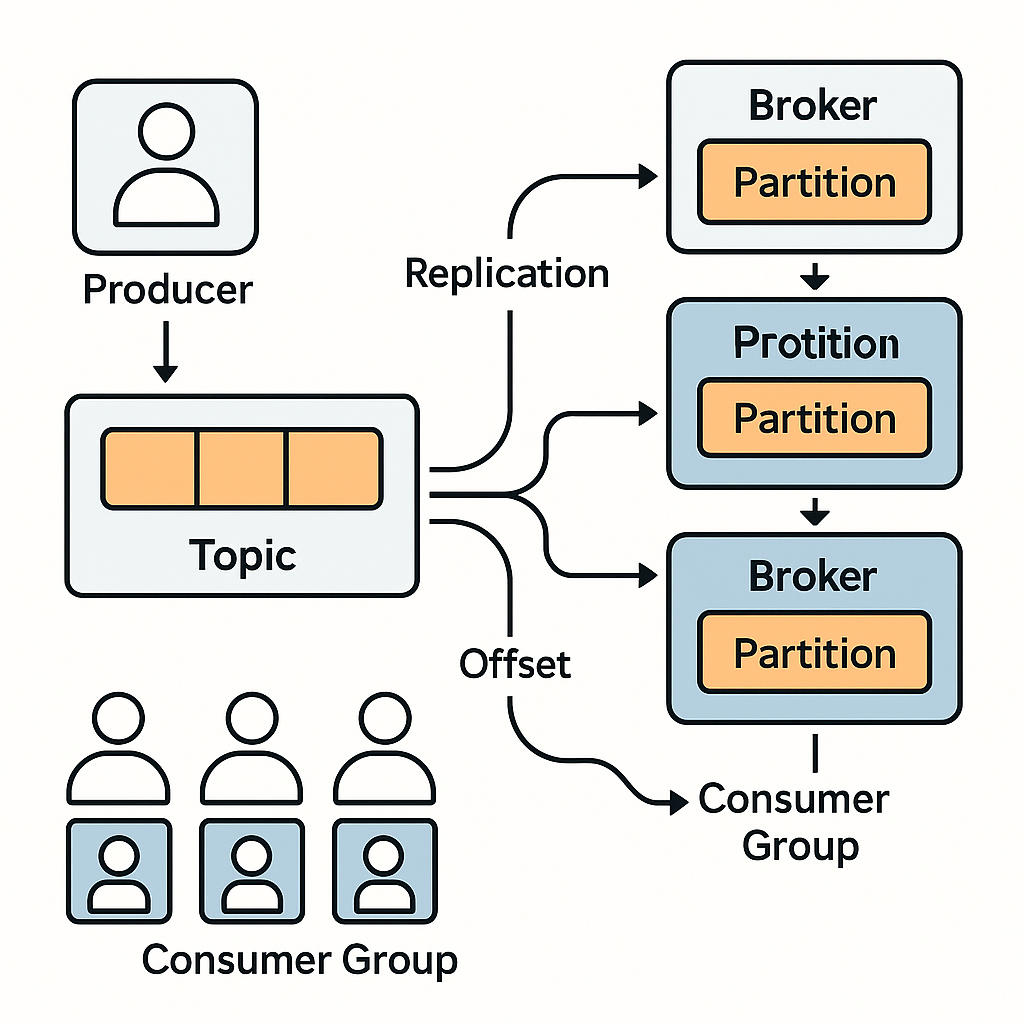
- Producer가 메시지를 Topic에 전송
- Topic은 여러 Partition으로 나뉘어 서로 다른 브로커에 분산 저장
- Leader 브로커에서 Follower 브로커로 복제(replication) 수행
- Consumer Group 내 컨슈머들이 파티션을 나눠 읽어 부하 분산
- 각 컨슈머는 Offset을 관리해 메시지 재생(replay) 가능
그렇다면 다른 메시지 큐 시스템과 비교해 보았을 때 카프카는 어떤 다른 장점이 있을까요?
Kafka vs 메시지 큐 시스템
| 서비스 | 요약 | 장점 | 단점 |
|---|---|---|---|
| Apache Kafka | 분산 로그(Log) 기반 스트리밍 플랫폼 | - 초당 수백만 건 처리 가능한 높은 처리량 - 파티션 단위 수평 확장 용이 - 데이터 복제·내구성 보장 - 오프셋 기반 재생 기능 |
- 운영·튜닝 복잡도 높음 - 초기 학습 곡선 가파름 |
| RabbitMQ | AMQP 프로토콜 기반 메시지 브로커 | - 풍부한 라우팅·토폴로지 기능 - 설정·사용법 비교적 간단 |
- 대량 메시지 처리 시 지연 증가 - 클러스터 확장 어려움 |
| Amazon SQS | AWS 관리형 메시지 대기열 서비스 (폴링 방식) | - 서버 관리 불필요, 무제한 확장 - SLA 기반 안정성 보장 |
- 폴링 지연 발생 - 복잡한 라우팅·필터링 미지원 |
| Google Pub/Sub | GCP 관리형 Pub/Sub 메시징 | - 글로벌 분산·자동 확장 - 완전 관리형, 서버리스 운영 |
- 벤더 락인 - 비용 사용량 비례 증가 |
| Redis Streams | Redis 내장 스트림 데이터 구조 | - 초저지연 응답(메모리 기반) - 간단한 API |
- 메모리 의존, 대용량 장기 보관 시 비용 부담 - 복제·영속성 직접 관리 필요 |
그럼에도 불구하고 Kafka를 선택한 이유
-
압도적 처리량
디스크 기반 배치 쓰기(batch write) 구조와 병렬 파티셔닝을 통해 초당 수백만 건의 메시지를 안정적으로 처리할 수 있어, 실시간 대용량 이벤트 파이프라인에 최적입니다. -
강력한 내구성·재생 기능
메시지를 로그로 영구 저장하고, 컨슈머 오프셋(offset) 조정만으로 과거 메시지를 즉시 재생할 수 있어, PoC 단계에서도 안전한 롤백과 재처리가 가능합니다. -
통합된 에코시스템과 확장성
Kafka Connect·Streams·KSQL 등 풍부한 도구를 통해 데이터베이스, 스토리지, 실시간 스트림 처리까지 하나의 플랫폼에서 해결할 수 있으며, 브로커·파티션 추가만으로 일관된 수평 확장이 가능합니다.
이처럼 Kafka는 성능, 내구성, 생태계 세 가지 핵심 강점을 바탕으로, 다른 메시징 솔루션으로는 구현하기 힘든 실시간 스트리밍 데이터 환경에서 특히 경쟁력을 발휘합니다.
배치 단위의 데이터 처리만 경험했기 때문에 이번 PoC는 대용량 + 실시간 데이터 처리를 경험하고자 카프카를 선택했습니다. 그럼 본격적으로 카프카 작업을 진행해봅시다!