추천시스템 이해하기
룰 베이스 기반 vs 협업 필터링 기반
추천시스템 이해하기
추천시스템이란?
사례
- 유튜브 개인화 추천
- 후보군 : 구독 채널 기반, 검색어 등 / 실시간 인기 영상, 새로운 영상, 나와 비슷한 행동을 보이는 고객들의 최근 영상 등
- 넷플릭스 테마별 큐레이팅 추천
- 사용자 선택이 제한적
- 다양한 테마를 보여주며 큐레이팅 + 개인화 추천
- 요기요
- 탐색 기회를 높여주는 추천
- 명확한 선호가 없을 때 탐색 기회를 높여주는 추천
- 유저 컨텍스트가 중요한 추천
- 현재 위치, 배달 시간, 배달료의 컨텍스트가 선택에 영향을 미치는 서비스
- 탐색 기회를 높여주는 추천
→ 추천시스템은 저마다의 목적과 배경을 가지고 있다!
(정확한 취향 저격 or 많이 보여줘 or 하나만 잘걸려라) 비즈니스 특성을 어떻게 활용할 것인가가 더 중요
구조
- 서비스에 로그인 → 서버에 로그인 정보 전달 (입장) → 미리 만들어놓은 데이터와 연결된 추천 API 사용 → 서버에 전달 (추천 내용) → 사용자 화면에 뿌려짐
추천 시스템 디자인
추천 서비스의 기획 과정
- PO or Data Scientist가 추천 서비스를 분석(로그 데이터를 분석)
- Google Data Studio / Tableau / Excel 사용
- 분석 결과를 가지고 가설을 설정하고 기획함
- 디자인 시안 및 추천 모델의 성격 설정
- 추천 서비스 개발 : app단에서 보여지는 개발, back에서 동작하는 api 개발
데이터 레이크 구축 과정
- 서비스 데이터 수집
- 사용자의 로그 행동 데이터를 수집 (누가 뭘 클릭했는지, 언제 얼마나 클릭했는지 등)
- 서버에 로그데이터를 저장
- 효율적 데이터 수집
- 사용자가 늘어나게 된다면 병렬적으로 서비스를 구축
- 분산된 데이터들을 관리 (Apache Kafka)
추천 서비스의 개발 과정
- 데이터 베이스에 수집된 데이터를 바탕으로…
- 추천 서비스 기획 : 신규 아이템 추천, 개인화 추천 등
- ML Engineer or Data Scientist 가 규칙 혹은 모델을 이용한 추천 알고리즘을 개발
- 알고리즘을 통해 추천 아이템을 추출 및 저장 (추천 API 서버:검색 엔진, DB, 실시간 연산 등)
- 추천 API 서버에서 다시 사용자에게 뿌려줌
추천 시스템을 평가하는 방법
평가 목표 설정하기
- CVR(Conversion Rate) : 얼마나 구매했는가
- 목록 중 실제로 구매까지 이어진 비율
- CTR(Click-Trough Rate) : 얼마나 클릭했는가
- 목록 중 유저가 열람한 비율
- Total Price : 이 추천시스템을 통해 얼마나 매출을 달성했는지
- User Rating : 이 추천시스템을 통해 얼마나 만족시켰는지
평가에 사용되는 로그데이터
- rating matrix : 사용자 - 아이템 매트릭스
- 시간순으로 raw가 생성됨 (시간을 잘 고려해야함)
- 명시적인 점수를 예상해 채워 넣는 것도 추천 시스템으로 사용 가능 (이론적으로는)
- 예측 점수 - 실제 점수로 추천 시스템 평가
- 암묵적 점수 (implicit feedback)
- 사용자의 명확한 피드백이 없는 경우, 구매/클릭으로 암묵적 점수를 평가
- N개 추천 중 X개 클릭 → CTR, N개 추천 중 X개 구매 → CVR
온라인 평가
- 명시적 점수 혹은 암묵적 점수를 바탕으로 추천 시스템 성능 평가
- A/B 테스트 : 추천 모델 A, 추천 모델 B 여러 로직을 통해 행동의 로그데이터를 바탕으로 추천시스템 성능 평가
→ 실제 이용자들의 행동으로 평가
오프라인 평가
- MSE 사용
- Confusion Matrix (범주형)
- Top K Recall
- 유저에게 추천한 K개 결과 중 Recall을 계산→ 추천 결과, 모델의 기술적 평가
- Top K Recall
룰 베이스 기반 추천 목록 만들기
오늘의 추천 (실시간 추천)
- 실시간 인기 아이템 보여주기
직원이 직접 고른 상품
→ 최근 N분동안 가장 조회(판매)된 상품
카테고리별 추천 (카테고리마다 광고상품 진열)
- 카테고리별 인기 상품
- 카테고리별 개인화 추천
→ 최근 N일, N주, N달 혹은 실시간 카테고리별 인기 상품을 진열
연관 추천 상품
- 연관 분석 기반 추천
- 광고 기반 추천
→ 연관 규칙 분석 (=장바구니 분석) : 여러 장바구니에서 특정 패턴 발견
연관 규칙 분석
- 데이터 예시
- 가설 : 맥주(조건절)를 산 사람이 두루마리(결과절)를 산다.
- 연관 규칙 분석의 계산 및 지표
- 지지도 Support
- 위 데이터에서 맥주의 지지도 4/10 (맥주 4개 포함됨)
- 규칙 지지도 : 조건절 → 결과절이 같이 가는 규칙 지지도
- 위 데이터에서 맥주를 사면 두루마리도 사는 규칙의 지지도 2/10
-
신뢰도 : 조건절 상황 하에 결과절 일어날 비율 (조건부확률 P(결과절 조건절)) - 위 데이터에서 규칙 지지도 / 지지도 = 2/4
- 향상도 : A와의 관계가 고려되어 규칙이 성립되는 경우
- Lift A→B : 신뢰도 / 결과절의 지지도
-
= P(결과절 조건절) / P(결과절) = 규칙 지지도 / (조건절 지지도 * 결과절 지지도) - 참고 : 1보다 커야 좋다[결론] 연관 규칙 분석은 인기 기반 추천 모델이다. 많이 나올수록 유리하니까!
- 지지도 Support
협업 필터링 기반 추천 목록 만들기
협업 필터링 vs 콘텐츠 기반 필터링
- 룰 기반 필터링
- 연관 분석
- 동일 카테고리
- 동일 브랜드 추천 등
-
협업 필터링
- 선호가 비슷한 사람(혹은 아이템)을 참고해 점수를 부여
- 유사한 구매 패턴으로 보이면 유사한 유저로 봄
[ 유저 기반 ]
- 미애와 가장 유사한 유저를 찾음
- 유사 유저의 점수를 활용
[ 아이템 기반 ]
- 존윅과 가장 유사한 영화를 찾음
- 유사 영화의 점수를 활용[ 전체 기반 - Matrix Factorization ]

KNN으로 추천 목록 만들기
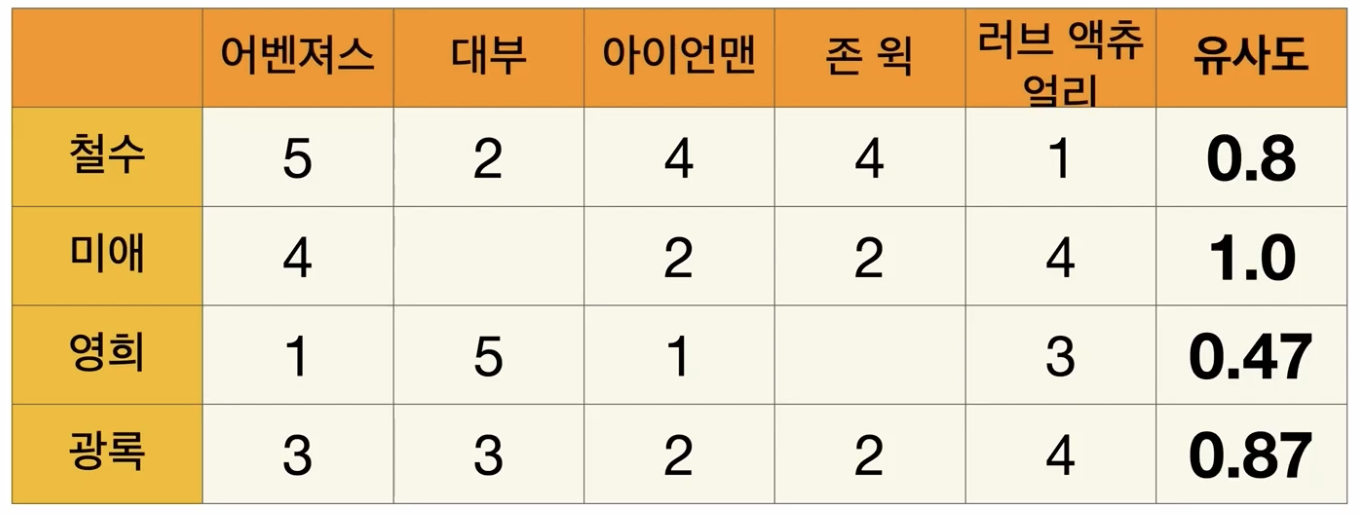
- 미애와 광록의 Cosine 유사도 계산 가능
- 점수가 없는 대부만 제외하고 유사도 계산
- 미애 - 대부 KNN을 기반한 점수는
- K = 2라고 가정 (광록과 철수가 가장 가까운 유저)
- (2(철수 대부 점수) * 0.8(철수 유사도) + 3(광록 대부 점수) * 0.87(광록 유사도)) / 0.8+0.87
- 만약 미애는 점수를 적게주고, 철수는 점수를 보통 주고, 광록은 점수를 많이 준다면?
- 2.4(미애의 평균점수) + ((2-3.2(철수 평균점수) * 0.8 + (3-2.8(광록 평균점수)) * 0.87 / 0.8+0.87)
이 기사는 저작권자의
CC BY 4.0
라이센스를 따릅니다.