Airflow와 Spark, Hive 기반 워크플로 그리기
학습을 위한 (현실적인) 빅데이터 처리 계획 세우기
Airflow와 Spark, Hive 기반 워크플로 그리기
아래 다이어그램은 EC2 기반으로 Airflow → Spark → Hive/Hadoop → HDFS DataNode 순서로 데이터 파이프라인을 구성한 그림입니다. 각 구성 요소의 역할과 실행 흐름을 단계별로 설명합니다.
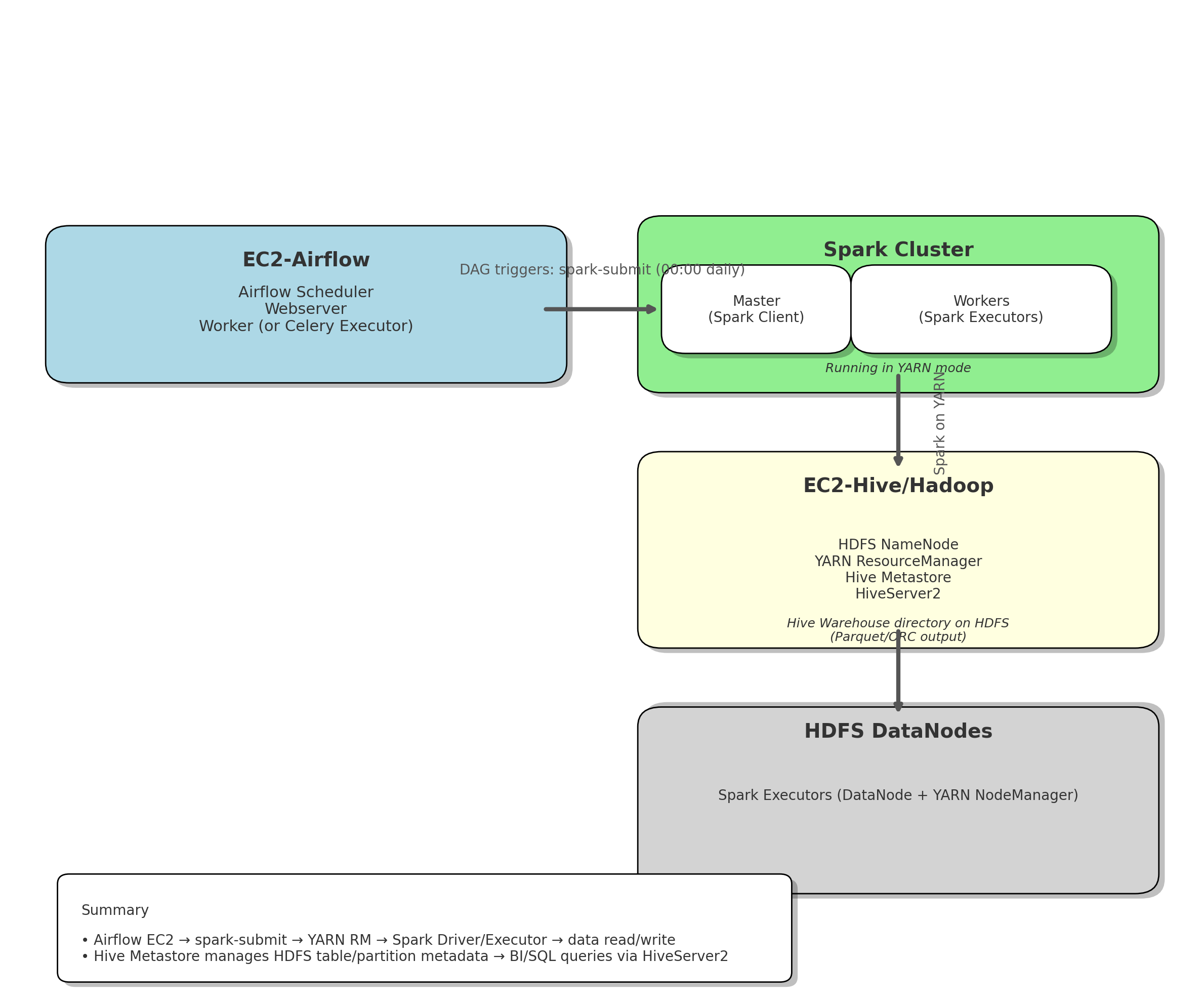
1. EC2-Airflow
- 역할
- Airflow 가 설치된 EC2 인스턴스로 매일 밤 00:00(서울 시간)에 설정된 DAG가 자동으로 실행되도록 스케줄링을 담당합니다.
- 주요 동작 흐름
- Airflow 스케줄러가 예약된 시간(UTC 15:00, KST 00:00)에 DAG를 트리거
- DAG 내의 Operator가 필요한 명령을 호출
- Spark 작업을 수행할 Spark Cluster로 배치 job 요청
- 실행 결과를 모니터링하고, 오류 발생 시 알림 처리(이메일/슬랙 등)
2. Spark Cluster
- 구성
- EC2 인스턴스 중 Spark Client(혹은 Spark Master 역할)를 별도 운영하고,
- 실제 계산은 Hadoop 클러스터의 DataNode 위에서 실행되는 Spark Executor가 수행합니다.
- 모드: Spark on YARN
- Spark Driver와 Aux 애플리케이션(AM)은 YARN ResourceManager에 의해 컨테이너로 실행되고,
- Executor는 YARN NodeManager 컨테이너로 올라가서 병렬 계산을 수행합니다.
- 주요 동작 흐름
- Airflow가 Spark Driver를 YARN ResourceManager에 제출
- YARN RM이 Spark Driver를 위한 컨테이너
ApplicationMaster를 할당 - Driver(ApplicationMaster)가 Executor N개, CPU X개, 메모리 YGB 등의 자원을 YARN RM에 요구
- YARN RM이 NodeManager 위에 Executor 컨테이너를 할당하고,
- 각 Executor가 HDFS에 저장된 JSON을 읽어 분석—데이터 정제, 스키마 변환, 파티셔닝 등 수행
- 분석된 결과를 Parquet/ORC 포맷으로 HDFS Hive Warehouse 디렉터리에 저장
- Driver가 모든 Executor의 작업 완료를 확인하고, 성공/실패 상태를 Airflow로 반환
3. EC2-Hive/Hadoop
- 역할
- Hadoop NameNode + YARN ResourceManager가 실행되는 마스터 노드로 Hive Metastore와 HiveServer2도 동시에 띄워서 Hive 테이블 메타데이터와 SQL 인터페이스를 관리합니다.
- HDFS 위에
/user/hive/warehouse/…디렉터리를 생성·소유하고, Spark이 쓴 Parquet/ORC 파일을 Hive 테이블 형식으로 유지합니다.
- 주요 구성 요소
- HDFS NameNode
- HDFS 전체 파일블록 메타데이터를 관리(어떤 DataNode에 어느 블록이 저장되었는지)
- YARN ResourceManager
- Spark(및 향후 다른 YARN 애플리케이션)의 자원을 통합 배분
- Hive Metastore
- 테이블 스키마, 파티션 정보, HDFS 디렉터리 매핑 정보를 RDB(MySQL 등)에 저장
- HiveServer2
- 외부 BI/SQL 클라이언트(JDBC/ODBC 등)가 접속해 HiveQL 쿼리를 실행할 수 있는 Thrift 인터페이스
- HDFS NameNode
4. HDFS DataNodes (Spark Executors)
- 역할
- Hadoop DataNode와 YARN NodeManager 역할을 하는 EC2 워커 노드로
- Spark Executor가 올라가서 분산 계산을 수행하고 HDFS 블록을 로컬 디스크에 저장하거나 읽습니다.
- 설치 항목
- Hadoop DataNode
- HDFS 블록을 저장하고, NameNode와 주기적으로 핑(heartbeat)으로 상태를 공유
- YARN NodeManager
- ResourceManager가 할당한 컨테이너(Executor) 실행 및 자원(메모리/CPU) 관리
- Spark Executor
- Driver로부터 전달된 Task를 병렬 실행
- 입력 데이터를 HDFS에서 로컬 메모리로 읽어와 in-memory 연산
- 계산 결과(Parquet/ORC 파일)를 다시 HDFS에 저장
- Hadoop DataNode
- 데이터 흐름 예시
- Spark Driver의 지시에 따라, Executor들이 HDFS DataNode 로컬 디렉터리에서 JSON 파일을 읽음
- 메모리에 데이터를 캐시하여 반복 연산을 수행하거나, 바로 변환하고 집계
- 최종 결과를 Hive Warehouse 경로에 Parquet/ORC 포맷으로 저장 → Hive Metastore로 파티션 추가
- 결과 조회 시 HiveServer2를 통해 외부 쿼리 또는 BI 툴에 응답
요약
- Airflow EC2
- Daily 00:00에 필요한 명령으로 Spark 애플리케이션을 제출 → Spark Cluster에 배치 Job 요청
- Spark Cluster (Spark on YARN)
- YARN ResourceManager가 Driver(AM)을 실행 → Driver가 Executor 컨테이너 요청 → NodeManager에서 Executor 실행
- Executor들이 HDFS DataNode에서 JSON을 읽어 분석 → Parquet/ORC 결과를 HDFS Hive Warehouse에 저장
- EC2-Hive/Hadoop
- Hive Metastore가 HDFS 테이블·파티션 메타데이터를 관리 → HiveServer2를 통해 SQL/BI 쿼리 제공
- HDFS NameNode와 YARN RM이 전체 클러스터 자원·파일 저장소를 통합 관리
- HDFS DataNodes
- Spark Executor가 올라가 실제 계산을 수행하고, 로컬에 블록을 캐시하여 병렬 연산
- 계산된 결과 파일을 HDFS에 저장 → Hive 테이블과 연동되어 조회·분석용 데이터웨어하우스로 활용
이 설계를 통해 Airflow가 스케줄링 → Spark on YARN이 분산 실행 → Hive/Hadoop이 저장·메타데이터 관리 → HDFS DataNode가 실제 연산으로 이어지는 전체 파이프라인을 한눈에 파악할 수 있습니다.
이후는 이 파이프라인을 구체화하고 실제로 구성하는 과정을 진행하면서 정리해보려고 합니다. 파이팅!
이 기사는 저작권자의
CC BY 4.0
라이센스를 따릅니다.