웹 클릭스트림 수집하기 :) 주간 회고 & 로컬 테스트
카프카 클러스터 띄우고 블로그 클릭스트림을 ingest api로 보내기까지
웹 클릭스트림 수집하기 :) 주간 회고 & 로컬 테스트
작심삼일 이랬던가
혼자서 삽질하다 보면 사기가 조금 떨어집니다. 그치만 작심을 삼일마다 반복하면서 매일 조금씩 나아가는 마음으로 노력해야겠습니다. 오늘은 금주의 진행상황 전체를 로컬에서 테스트해보려고 합니다.
금주 회고
우선 지금까지 한 내용을 정리해보자면 다음과 같습니다.
- 수요일 - 개인 블로그를 만들고 로그 이벤트를 심었습니다. 만들어진 로그 이벤트는 람다로 갑니다.
- 목요일 - 카프카 클러스터를 로컬에서 테스트해보고 EC2에도 띄워봅니다. (with IaC)
- 금요일 - 로그 이벤트를 목적에 맞게 더 구체적으로 만들어 심었습니다.
그럼 지금까지의 내용을 직접 실행시키기 위해서
- 카프카 클러스터를 띄우고 토픽을 만든다.
- 프로듀서 역할을 할 fastapi을 실행한다.
- 프론트를 띄워서 블로그를 접속한다.
- New 카프카 컨슈머가 데이터를 저장하도록 한다.
이와 같은 단계별 결과를 공유하며 한 주를 정리하려고 합니다.
전체 구조를 요약하자면 다음과 같습니다.
flowchart TB
subgraph "Local Host"
A["Jekyll Frontend<br>Click Event (JS)"] -->|"POST /ingest"| B["FastAPI Ingest API"]
B -->|"produce to Kafka"| C["Kafka Broker (Docker)"]
C --> D["Kafka Topic: clickstream"]
D --> E["Kafka Consumer<br>consumer_store.py"]
E --> F["output/clickstream_output.jsonl"]
end
로컬 작업물 정리하고 버전 관리(git)
그러기에 앞서 로컬에서 작성한 코드들의 버전을 관리할 필요가 있을 것 같아 github repo를 만들고 업로드 했습니다.
- Kafka Ingest API: 로컬에서 카프카 구동하기
- EC2 Kafka AMI Infrastructure as Code (IaC): 카프카 설치 ami 만들기
- Private EC2 Infrastructure as Code (IaC): ami로 프라이빗 ec2 만들기
실행하기
자, 지금부터는 순서대로 실행하는 코드-결과 입니다.
1. 카프카 클러스터를 띄우고 토픽을 만든다.
1
2
3
4
5
6
7
8
9
10
11
$ docker-compose up -d
[+] Running 3/3
⠿ Network kafka-ingest_default Crea... 0.1s
⠿ Container kafka-ingest-zookeeper-1 Started 0.4s
⠿ Container kafka-ingest-kafka-1 St... 0.6s
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
554e951918e2 confluentinc/cp-kafka:7.4.1 "/etc/confluent/dock…" 6 seconds ago Up 5 seconds 0.0.0.0:9092->9092/tcp kafka-ingest-kafka-1
b6e269a6dc23 confluentinc/cp-zookeeper:7.4.1 "/etc/confluent/dock…" 6 seconds ago Up 5 seconds 2181/tcp, 2888/tcp, 3888/tcp kafka-ingest-zookeeper-1
$ docker exec -it kafka-ingest-kafka-1 kafka-topics --create --topic clickstream --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1
Created topic clickstream.
2. 프로듀서 역할을 할 fastapi을 실행한다.
1
2
3
$ source .venv/bin/activate
$ nohup uvicorn ingest_kafka:app --reload --port 8000 > ingest_kafka.log &
[1] 81854
- 백그라운드 실행
- log 파일로 과정 기록
3. 프론트를 띄워서 블로그를 접속한다.
1
2
3
# annmunju.github.io 폴더로 이동
$ nohup bundle exec jekyll serve > front.log &
[1] 86312
- 동일하게 log 파일로 과정 기록
- 프론트에서 ingest api로 요청을 보내고 있는지 확인
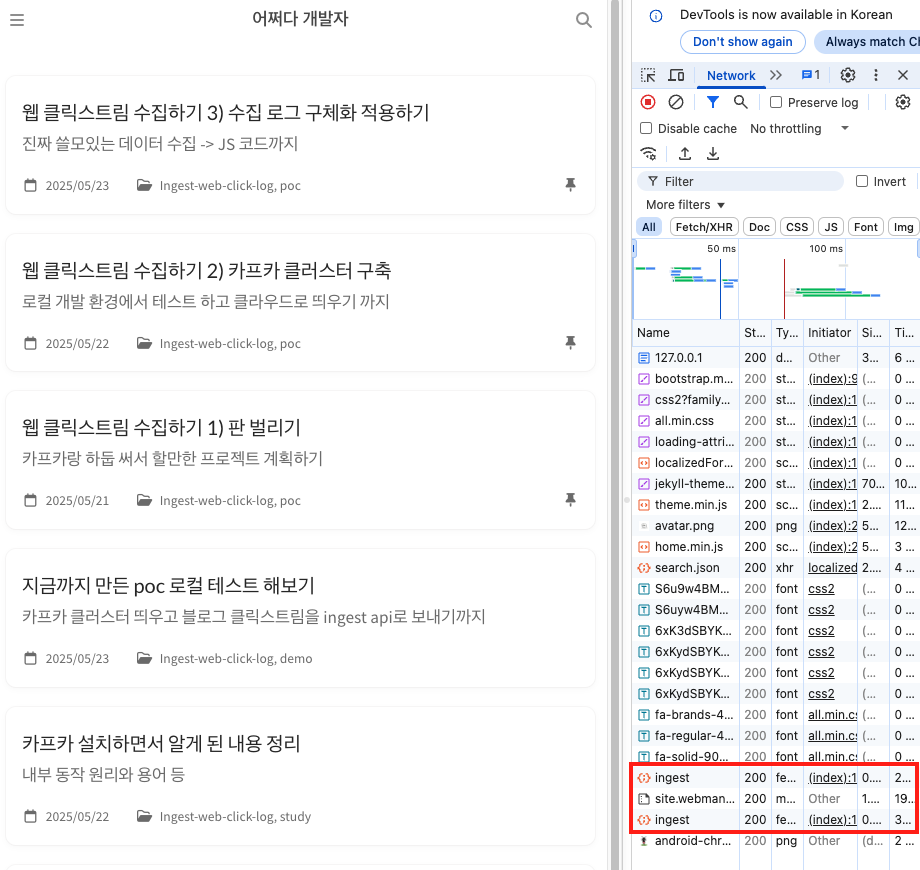
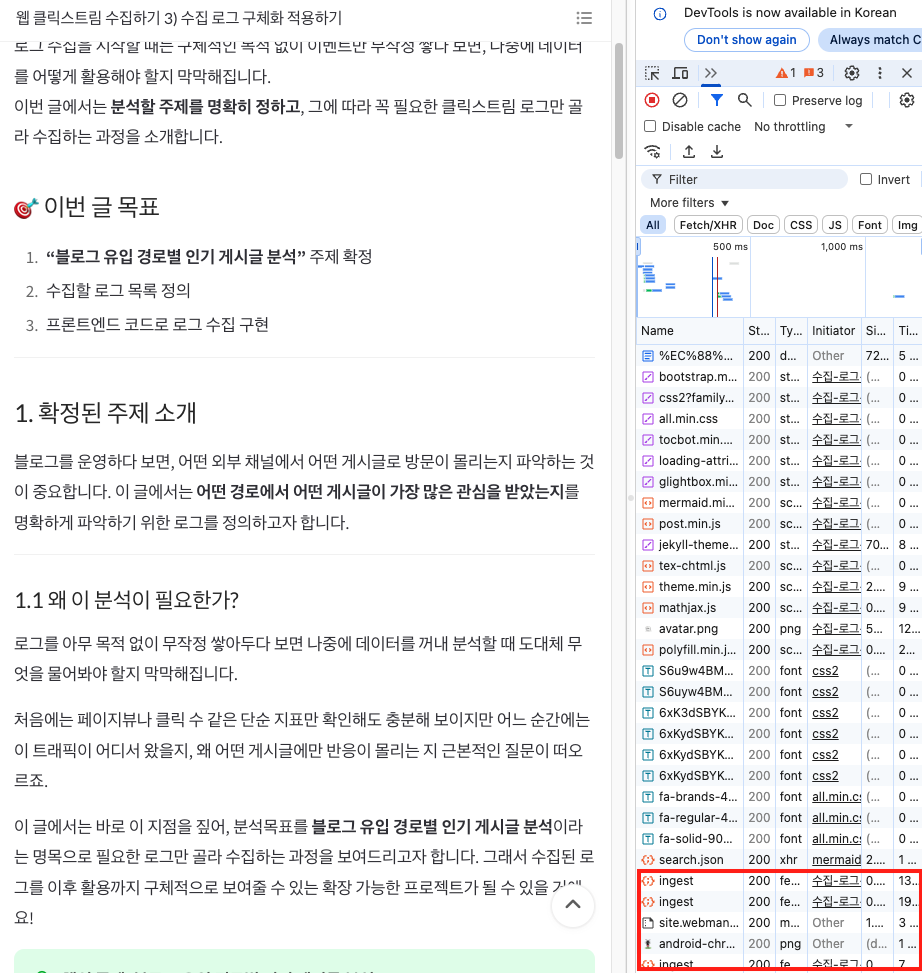
- ingest api 로그 확인
1 2 3 4 5
... INFO:ingest:Produced to clickstream: {'event': 'time_on_page', 'timestamp': '2025-05-23T08:01:07.007Z', 'path': '/posts/%EB%A1%9C%EC%BB%AC-%ED%85%8C%EC%8A%A4%ED%8A%B8/', 'referrer': 'http://127.0.0.1:4000/', 'duration': 19882} INFO: 127.0.0.1:49252 - "POST /ingest HTTP/1.1" 200 OK INFO:ingest:Produced to clickstream: {'event': 'session_end', 'timestamp': '2025-05-23T08:01:07.007Z', 'path': '/posts/%EB%A1%9C%EC%BB%AC-%ED%85%8C%EC%8A%A4%ED%8A%B8/', 'referrer': 'http://127.0.0.1:4000/'} INFO: 127.0.0.1:49254 - "POST /ingest HTTP/1.1" 200 OK
4. New 카프카 컨슈머가 데이터를 저장하도록 한다.
컨슈머 코드를 미리 만들어두지 않아서 일단 로컬에 저장하는 형태로 코드를 구현해 실행해보았습니다. 커밋 내역
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# consumer_store.py
import json
import os
from pathlib import Path
from confluent_kafka import Consumer, KafkaError
# Kafka 설정
KAFKA_BOOTSTRAP = os.getenv("BOOTSTRAP_SERVERS", "localhost:9092")
KAFKA_TOPIC = os.getenv("KAFKA_TOPIC", "clickstream")
# 출력 경로 설정
OUTPUT_DIR = Path("output")
OUTPUT_DIR.mkdir(exist_ok=True)
OUTPUT_FILE = OUTPUT_DIR / "clickstream_output.jsonl"
# Kafka Consumer 설정
consumer_conf = {
"bootstrap.servers": KAFKA_BOOTSTRAP,
"group.id": "clickstream-consumer-group",
"auto.offset.reset": "earliest",
}
consumer = Consumer(consumer_conf)
consumer.subscribe([KAFKA_TOPIC])
print(f"Consuming from topic '{KAFKA_TOPIC}'...")
try:
with open(OUTPUT_FILE, "a", encoding="utf-8") as f:
while True:
msg = consumer.poll(1.0)
if msg is None:
continue
if msg.error():
if msg.error().code() != KafkaError._PARTITION_EOF:
print("Error:", msg.error())
continue
payload = msg.value().decode("utf-8")
print("Received:", payload)
f.write(payload + "\n")
except KeyboardInterrupt:
print("Stopped by user.")
finally:
consumer.close()
- output/ 디렉토리에 로그를 저장
- clickstream_output.jsonl 파일에 Kafka 메시지를 한 줄씩 저장
- 메시지를 계속 실시간으로 소비하며 콘솔 출력과 저장 수행
저장된 로그 결과는 다음과 같았습니다.
1
2
3
4
$ tail -3 output/clickstream_output.jsonl
{"event": "scroll_event", "timestamp": "2025-05-23T08:22:31.045Z", "path": "/posts/%EC%B9%B4%ED%94%84%EC%B9%B4-%EA%B0%9C%EB%85%90/", "referrer": "http://127.0.0.1:4000/", "scroll_percentage": 0}
{"event": "scroll_event", "timestamp": "2025-05-23T08:22:32.278Z", "path": "/posts/%EC%B9%B4%ED%94%84%EC%B9%B4-%EA%B0%9C%EB%85%90/", "referrer": "http://127.0.0.1:4000/", "scroll_percentage": 4}
{"event": "scroll_event", "timestamp": "2025-05-23T08:22:33.571Z", "path": "/posts/%EC%B9%B4%ED%94%84%EC%B9%B4-%EA%B0%9C%EB%85%90/", "referrer": "http://127.0.0.1:4000/", "scroll_percentage": 5}
[번외] 리소스 정리하기
1
2
3
4
5
6
# 카프카 종료
docker-compose down
# ingest api 종료
$ kill -9 $(ps -fu ahnmunju | grep uvicorn | awk '{print $2}')
# 프론트 종료
$ pkill -f jekyll
최종 결과
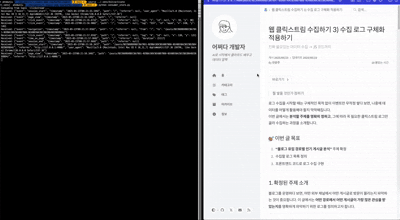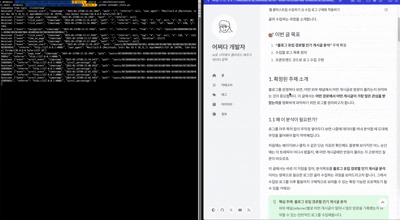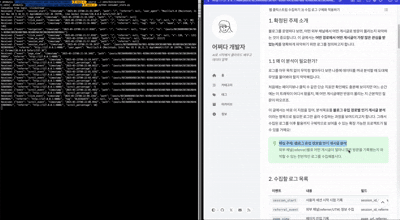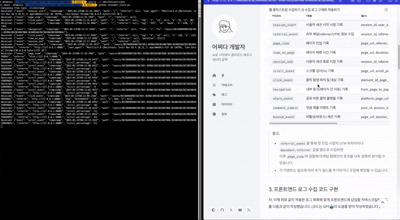
- 왼쪽은 컨슈머 동작시에 나타나는 화면입니다.
- 오른쪽 블로그에 접속해서 보거나, 클릭하거나, 스크롤 하면 이에 대한 로그 이벤트가 발생합니다.
- 로그 이벤트는 왼쪽 컨슈머에 출력됩니다.
회고
이번 주는 “내가 직접 로그 파이프라인을 만들 수 있다”는 자신감을 얻은 한 주였습니다. 혼자였지만 매일 정리하고, 실패하더라도 되짚어가며 결국 Kafka에 로그를 보내고 소비하는 전 과정을 완성했습니다. 다음 주에는 로그를 클라우드 환경에서 저장하고 쌓인 데이터를 분석 / 시각화 하는 전체 과정을 큰 그림으로 그리고 각각을 완성해나갈 계획입니다. 끝!
이 기사는 저작권자의
CC BY 4.0
라이센스를 따릅니다.