웹 클릭스트림 수집하기 4) EC2 카프카 & 컨테이너 Lambda 배포
카프카에 S3 Sink 커넥터를 붙이고 Lambda로 프로듀서 생성하기
이제 클라우드 환경에서 람다로 데이터 수집 본격화
이번 주에는 EC2에 띄운 Kafka 클러스터를 기반으로 GitHub Pages에 호스팅된 프론트엔드에서 발생하는 클릭스트림 로그를 AWS Lambda로 수집하는 프로세스를 완성할 계획입니다.
Lambda 프로듀서 함수가 Kafka 토픽에 메시지를 전송하면, 동일한 EC2에서 실행 중인 Kafka Connect S3 Sink 커넥터가 해당 토픽을 소비해 S3에 배치 적재하는 end-to-end 파이프라인을 구축해봅니다.
아키텍처 그리기

- 클라이언트 → API Gateway
- GitHub Pages(Jekyll)로 호스팅된 프론트엔드에서 JS 클릭스트림 이벤트가 발생하면 퍼블릭 API Gateway 엔드포인트로 HTTP 호출이 들어옵니다.
- API Gateway는 Lambda Kafka Producer 함수를 트리거합니다.
- Lambda Producer
- 함수 코드가 Kafka 클러스터의 토픽(clickstream)에 메시지를 프로듀싱합니다.
- EC2 Kafka 클러스터
- EC2 인스턴스 위에서 Zookeeper + Kafka Broker가 함께 동작합니다.
- 이 클러스터가 프로듀서가 보낸 메시지를 저장·관리합니다.
- Kafka Connect S3 Sink (동일 EC2)
- EC2에서 Kafka Connect를 실행하고 S3 Sink 커넥터를 설정합니다.
- 이 커넥터가 clickstream 토픽을 소비해 지정된 주기(Flush size)마다 S3 버킷에 JSON/Parquet 파일로 배치 적재합니다.
- Amazon S3
- 최종적으로 적재된 로그 데이터는 S3 버킷에 저장되어, 후속 분석 및 시각화에 활용할 예정입니다.
🎯 이번 글 목표
다음과 같은 아키텍처를 기반으로, 오늘은 ec2에 띄운 카프카의 설정을 마치고 lambda를 배포해야합니다.
- Lambda Producer 배포하기
- 컨테이너 형태로 배포하기 (with ECR)
- S3 버킷 생성하기
- 버킷 생성을 위한 데이터 저장 방식 결정
- 버킷 보호를 위한 규칙 설정
- EC2 카프카 배포하기
- 퍼블릭 서브넷 EC2에 카프카 설정을 끝내고
- S3 Sink 커넥터를 설정하기
1. Lambda Producer 생성하기
람다에 kafka 프로듀서 코드를 도커 컨테이너 이미지로 작성하고 ECR로 올려보겠습니다.
a. ecr과 lambda 만들 terraform 파일작성
순서는 이렇습니다. 먼저 ecr을 만들고 나서 그 이후에 ecr에 컨테이너 이미지를 push 하면 해당 이미지를 람다로 실행하게 됩니다. 그러기 위해 가장 먼저 테라폼 파일을 작성했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# ecr.tf
provider "aws" {
region = var.region
}
resource "aws_ecr_repository" "kafka_producer" {
name = "kafka-producer"
image_scanning_configuration {
scan_on_push = true
}
}
# 수명주기 정책 추가 (3개 이상 이미지 쌓이면 제거됨)
resource "aws_ecr_lifecycle_policy" "kafka_producer_policy" {
repository = aws_ecr_repository.kafka_producer.name
policy = <<POLICY
{
"rules": [
{
"rulePriority": 1,
"description": "Keep only the most recent 3 images",
"selection": {
"tagStatus": "any",
"countType": "imageCountMoreThan",
"countNumber": 3
},
"action": {
"type": "expire"
}
}
]
}
POLICY
}
그리고 아래와 같이
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# lambda.tf
... # iam 설정
resource "aws_lambda_function" "kafka_producer" {
function_name = "kafka-producer"
package_type = "Image"
image_uri = "${aws_ecr_repository.kafka_producer.repository_url}:latest"
role = aws_iam_role.lambda_exec.arn
architectures = ["arm64"]
environment {
variables = {
BOOTSTRAP_SERVERS = "<kafka-server>:9092"
KAFKA_TOPIC = "clickstream"
}
}
}
먼저 컨테이너 이미지가 사용할 아키텍처를 arm64로 명시했습니다. 단순 연산에 유리하고 무엇보다 m1 맥북을 개발하는데 사용하고 있어 도커 테스트나 사용에 용이합니다.
그리고 ecr의 이미지를 사용하도록 작성했습니다. 하지만 아직 이미지가 올라가 있지 않아 terraform apply시 에러가 발생합니다.
람다 환경변수 중 BOOTSTRAP_SERVERS는 카프카 부트스트랩 서버의 주소를 입력해 람다 코드 내부에서 참조하도록 합니다.
b. Dockerfile 작성 및 컨테이너 이미지 빌드
다음과 같이 도커파일을 작성했습니다. 초기에는 lambda 이미지를 가져와(FROM) 사용하고자 했으나 잦은 에러와 디버깅이 어려워 파이썬이 사전 설치된 버전으로 사용했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# Dockerfile
FROM python:3.9-slim
# 1) 시스템 패키지
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential python3-dev librdkafka-dev ca-certificates \
&& rm -rf /var/lib/apt/lists/*
# 2) RIC(런타임 인터페이스 클라이언트) + 앱 deps 설치
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt awslambdaric
# 3) 앱 복사
COPY ingest_kafka.py .
# 4) ENTRYPOINT/CMD 설정
ENTRYPOINT ["python3", "-m", "awslambdaric"]
CMD ["ingest_kafka.handler"]
해당 도커에 포함된 앱 ingest_kafka.py은 기존에 작성했던 fastapi에 Mangum 라이브러리를 추가했습니다. 관련 정보는 블로그를 참고했습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# !/bin/bash
AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
AWS_REGION=$(aws configure get region || echo "ap-northeast-2")
export AWS_ACCOUNT_ID AWS_REGION
docker buildx build \
--platform linux/arm64 \
-t kafka-producer:latest \
--load \
.
docker tag kafka-producer:latest \
$AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/kafka-producer:latest
c. terraform 실행 및 ecr 이미지 업로드
모든 준비가 끝난 상황에서 순서에 맞게 ecr을 생성하고 이미지를 업로드한 후 람다를 생성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# !/bin/bash
terraform init
# ecr 생성
terraform apply -target=aws_ecr_repository.kafka_producer
# ecr 로그인
aws ecr get-login-password \
--region $AWS_REGION \
| docker login \
--username AWS \
--password-stdin $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com
# 레지스트리에 push
docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/kafka-producer:latest
# 나머지 람다 적용
terraform apply -auto-approve
해당 전체 과정을 통해 람다가 정상 배포됩니다. 카프카가 EC2에 정상적으로 띄워져 있어 람다 테스트 Json을 다음과 같이 작성하고 실행하면 바르게 전송되는 것을 확인할 수 있습니다.
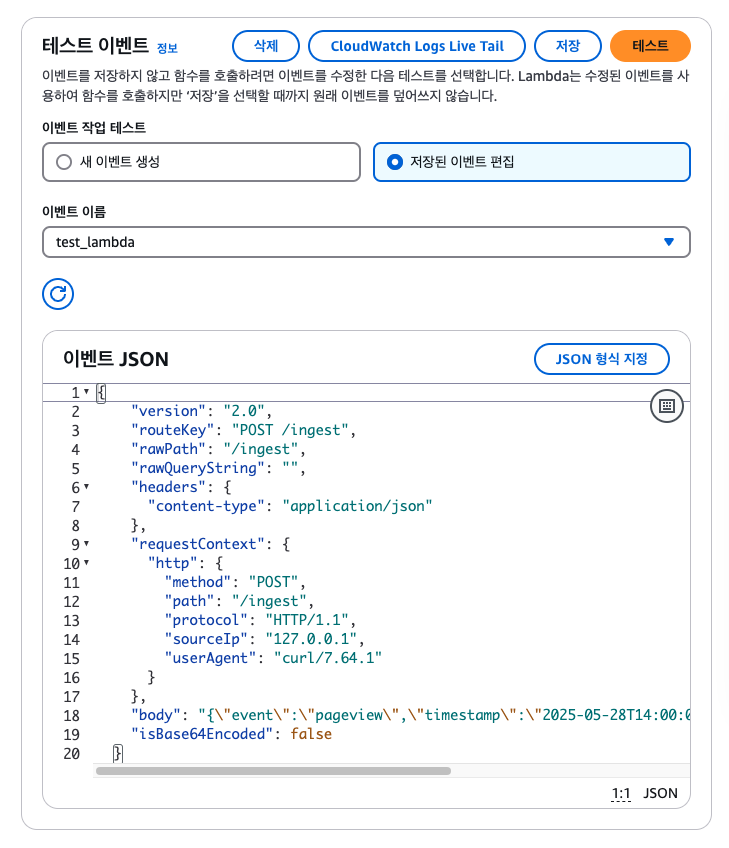

2. S3 버킷 생성하기
a. s3 버킷 생성
저는 S3의 경우 콘솔에서 버킷을 생성했습니다. 원본 파일과 가공 파일을 별도로 하기위해 버킷명은 -raw로 끝나도록 지정했습니다.
b. 버킷에 저장하기 위한 권한 & 역할 부여
구동중인 카프카만 해당 버킷에 접근할 수 있도록 정책을 생성하고 EC2에 해당 정책을 포함한 역할을 생성, 할당합니다.
- 버킷 접근 권한 정책 생성
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowS3ListAndGetLocation", "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetBucketLocation" ], "Resource": "arn:aws:s3:::your-bucket-name" }, { "Sid": "AllowS3Writes", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:AbortMultipartUpload", "s3:ListMultipartUploadParts" ], "Resource": "arn:aws:s3:::your-bucket-name/*" } ] }
- 권한을 역할에 포함시킨 후 해당 역할 EC2에 연결
위와 같은 접근 권한이 있는 정책을 생성해 역할에 붙여줍니다. 해당 역할은 EC2에 연결합니다.
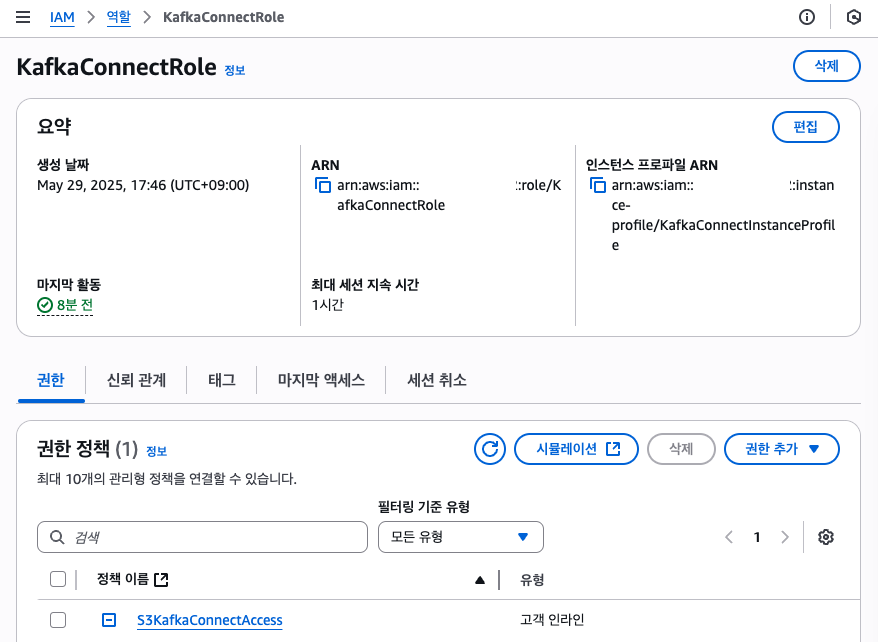
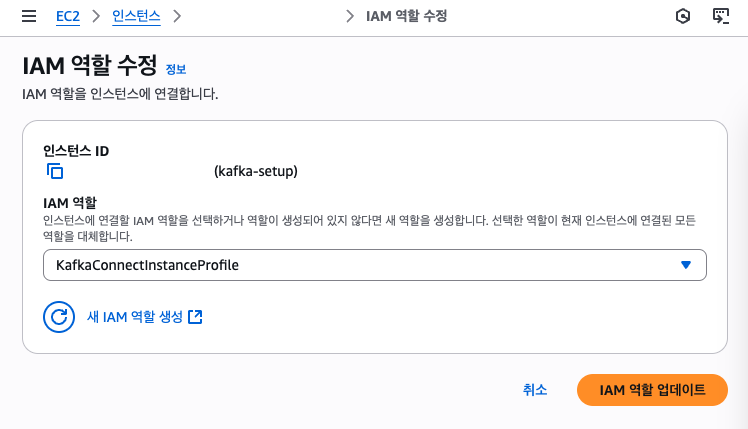
- 버킷 정책에 Principal 지정해 해당 역할로만 허용하게 설정 버킷 정책을 통해 EC2 역할만 허용하는 리소스 기반 접근 통제를 추가로 걸어 줍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowKafkaConnectRoleListBucket",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<id>:role/KafkaConnectRole"
},
"Action": [
"s3:ListBucket",
"s3:GetBucketLocation"
],
"Resource": "arn:aws:s3:::kafka-connect-s3-raw"
},
{
"Sid": "AllowKafkaConnectRoleWrites",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::<id>:role/KafkaConnectRole"
},
"Action": [
"s3:PutObject",
"s3:AbortMultipartUpload",
"s3:ListMultipartUploadParts"
],
"Resource": "arn:aws:s3:::kafka-connect-s3-raw/*"
}
]
}
위와 같은 설정을 버킷 정책에 적용하면 의도치 않은 권한 확장이나 외부 침입 시도를 효과적으로 방어할 수 있습니다.
설정을 마치면 EC2는 해당 버킷에 접속할 수 있게 됩니다!
3. EC2 카프카 배포하기
지난 게시글에는 카프카 브로커 (및 주피커)를 실행했습니다. 이번에는 커넥터를 추가해서 이 커넥터를 브로커에 연결해 기록을 읽고 S3 Sink로 데이터를 전송하는 전체 과정을 다뤄보겠습니다.
a. EC2에서 Kafka 설정 마무리
기존에 등록한 systemd를 활용해 띄워둔 kafka 브로커가 정상 작동되는지 확인합니다.
1
2
3
4
5
$ sudo systemctl status kafka.service
Loaded: loaded (/etc/systemd/system/kafka.service; enabled; vendor preset: disabled)
Active: active (running) since 목 2025-05-29 08:51:05 UTC; 28min ago
Main PID: 24437 (java)
CGroup: /system.slice/kafka.service
그리고 토픽을 출력해봅니다.
1
2
3
4
5
6
7
$ /opt/confluent/bin/kafka-topics --bootstrap-server localhost:9092 --list
clickstream
$ # 토픽 정보 출력
$ /opt/confluent/bin/kafka-topics --bootstrap-server localhost:9092 --describe --topic clickstream
Topic: clickstream TopicId: 8-L3WOkyRoWmHGZcfZRLUw PartitionCount: 1 ReplicationFactor: 1 Configs:
Topic: clickstream Partition: 0 Leader: 0 Replicas: 0 Isr: 0
b. Kafka Connect S3 Sink 커넥터 설정하기
우선 저는 Confluent Hub의 Amazon S3 Sink Connector을 직접 서버에 설치했습니다. Confluent Platform – self-managed 형식으로 ZIP 파일을 다운로드받아 카프카 EC2 서버에 전송한 뒤, 아래 순서대로 설정을 마무리했습니다.
- 플러그인 압축 해제 및 디렉터리 이동
1 2
# 서버로 ZIP 파일 전송 후 unzip confluentinc-kafka-connect-s3-10.6.5.zip -d /opt/kafka/plugins/
- standalone 설정 파일에 plugin.path 추가
1 2 3
# /opt/confluent/etc/kafka/connect-standalone.properties # (기존 항목에 추가) plugin.path=/opt/kafka/plugins/confluentinc-kafka-connect-s3-10.6.5
- quickstart-s3 설정 파일 복사
1
cp /opt/kafka/plugins/confluentinc-kafka-connect-s3-10.6.5/etc/quickstart-s3.properties /opt/confluent/etc/kafka/quickstart-s3.properties - 파일 구성 요소 수정
/opt/confluent/etc/kafka/quickstart-s3.properties1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
name=s3-sink connector.class=io.confluent.connect.s3.S3SinkConnector tasks.max=1 topics=clickstream s3.region=ap-northeast-2 s3.bucket.name=<버킷 이름> s3.part.size=67108864 flush.size=1000 storage.class=io.confluent.connect.s3.storage.S3Storage format.class=io.confluent.connect.s3.format.json.JsonFormat partitioner.class=io.confluent.connect.storage.partitioner.TimeBasedPartitioner schema.compatibility=NONE partition.duration.ms=3600000 path.format='year=!{timestamp:yyyy}/month=!{timestamp:MM}/day=!{timestamp:dd}/hour=!{timestamp:HH}' locale=ko_KR timezone=Asia/Seoul
- systemd 서비스 유닛 파일 생성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
[Unit]
Description=Kafka Connect Standalone (S3 Sink)
After=network.target
[Service]
Type=simple
User=ec2-user
ExecStart=/opt/confluent/bin/connect-standalone \
/opt/confluent/etc/kafka/connect-standalone.properties \
/opt/confluent/etc/kafka/quickstart-s3.properties
Restart=on-failure
RestartSec=10
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
- 이제 다음을 실행하면 systemd 데몬이 다시 실행되고 서비스가 활성화 됩니다.
1
2
3
4
5
6
7
8
9
10
$ sudo systemctl daemon-reload
$ sudo systemctl enable kafka-connect.service
$ sudo systemctl start kafka-connect.service
$ # 서비스 상태 확인
$ sudo systemctl status kafka-connect.service
Loaded: loaded (/etc/systemd/system/kafka-connect.service; enabled; vendor preset: disabled)
Active: active (running) since 목 2025-05-29 08:54:45 UTC; 44min ago
Main PID: 28748 (java)
CGroup: /system.slice/kafka-connect.service
🚀 결론 및 이후 계획
이번 글에서는
- 컨테이너 Lambda Producer를 ECR + Terraform으로 배포하고,
- S3 버킷을 raw 데이터용으로 생성·권한 설정하며,
- Kafka Connect S3 Sink 커넥터를 systemd 서비스로 자동화해
clickstream토픽을year=/month=/day=/hour=구조로 S3에 배치 적재
까지 end-to-end 파이프라인을 완성했습니다. 재부팅 후에도 systemd가 자동 기동합니다. 다음은 S3 업로드를 검증하고 해당 데이터를 HDFS에 파일로 저장하고 배치 분석을 실행하는 단계를 이어가겠습니다.